In 2010, the very first Imagenet Large Scale Visual Recognition Challenge (ILSVRC) was held. The goal of the challenge was for participants to classify objects in an image using an algorithm. That year, the top-5 error rate was 28%, falling to 26% in 2011. In 2012, however, the first deep Convolutional Neural Network (CNN) was introduced to the competition, blowing away its competitors with the top-5 error rate dropping to just 16%! From there on, every subsequent winning algorithm was a CNN (including in 2013, when Clarifai won all top 5 places!) showing just how good CNNs are at image classification. But if you’re wondering now what CNNs even are or why they’re so good, you’ve come to the right place.
CNNs are a special type of neural network (usually deep) that are used for computer vision tasks (if you haven’t read my Deep Learning blog post yet, you may want to check it out as it will be helpful for understanding the rest of this post.)
The purpose of a CNN is to transform raw pixels into meaningful concepts that humans (or algorithms!) can understand. While this may not seem like a very difficult task, consider the following very simple image from the Modified National Institute of Standards and Technology (MNIST) dataset.
It’s a “four,” something many humans can easily tell. But what does it look like to a machine? 784 values between 0 and 255.
Being a 28 x 28 grayscale pixel image, each of the 784 values can take a value between 0 (black) and 255 (white.) If you were only given a list of 784 numbers and told “what number is this?” it would likely take you a substantial amount of time to answer. What if we have a 1080p full-color image? Well, if we do the same math, that equals over 2 million pixels, each of which can have a value between 0 and 255 for each color channel. That’s over 16 million different colors for each of the 2 million pixels! As humans, we are able to just look at the grayscale picture itself and immediately make sense of what we’re looking at. With CNNs though, machines are now able to do the same thing.
So how does this work? The deep architecture of the neural networks allows us to first identify low-level features from the image, and use these low-level features to generate higher and higher level features that can encode to concepts that are understandable to humans, like a cat or dog.
A good question. Let’s consider a simple classification network trained to identify the ten handwritten digits between 0 and 9. We will use Yann Lecun's LeNet architecture for it (pictured below.) We can think of this as having 8 different images. As we travel through each layer of the network, we’ll talk briefly about them.
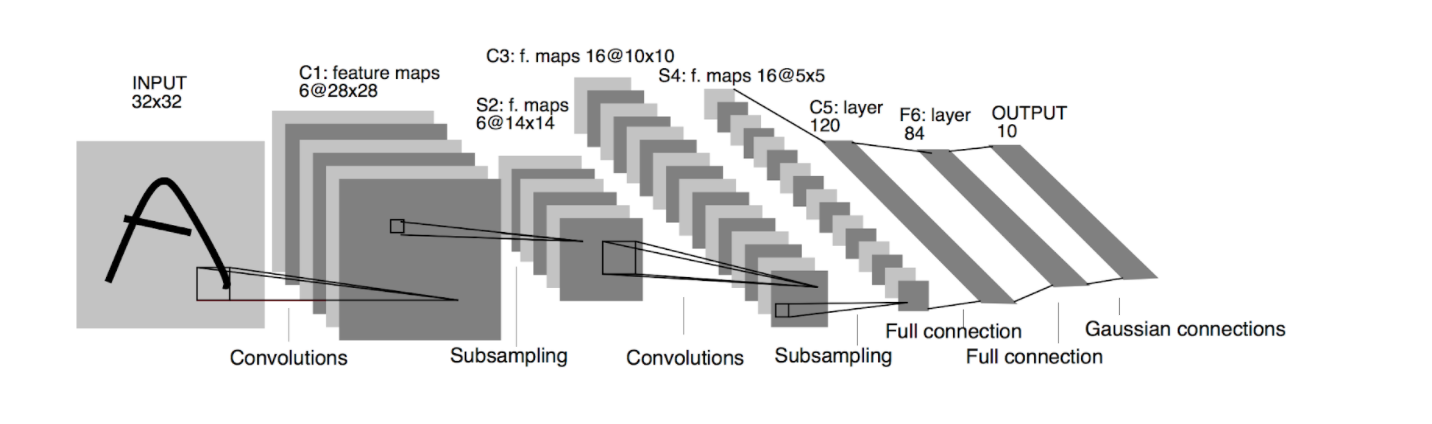
1) Input- This layer is 32 pixels wide, 32 pixels high, and only 1 pixel deep because it’s grayscale. Next layer!
2) C1 (Convolutional 1) layer- This layer is 28 pixels wide, 28 pixels high, but 6 pixels deep. Between the input layer and this layer, a convolutional operation is performed on the input pixels (the mathematics behind it is beyond the scope of this post,) but the process turns 1 channel of raw pixels into 6 channels of features. As humans who are used to grayscale (1 pixel deep) images or full color (3 pixels deep) images, this can be confusing. The 6-pixel depth here doesn’t refer to a specific color, but instead a feature extracted from the previous layer. Since this is the first layer, the features learned will be simple, like a vertical line, a horizontal line, a curvy line, etc. These features will be used later! The height and width shrunk slightly due to padding around the edges of the image.
3) S2 (Subsampling 2) layer- This layer is 14 pixels wide, 14 pixels high, but still 6 pixels deep. The features are the same, but they are a quarter of the size! (even though each individual side of the rectangles are half the size, when multiplied together 142 = 196, 282 = 784, so a quarter the size). Subsampling (or max pooling as it’s sometimes called) serves two purposes in a CNN. Firstly, it reduces the feature map size used later in the network. Because memory and speed can be a concern with very large CNNs, we want them to be as small as possible. Secondly, subsampling only passes on the most prominent features to later layers of the network, while suppressing minor features. Imagine you are trying to pick what you want to order for dinner. Do you want to make your decision based on 1 key variable (how good is the food) or 4 variables which may not all be important (how good is the food, does the restaurant owner like dogs or cats, what is the third letter of the restaurant, what kind of vehicle will the driver use)? Subsampling layers allow us to ignore irrelevant features.
4) C3 (Convolutional 3) layer- This layer is 10 pixels wide, 10 pixels high, and 16 pixels deep. It shrunk slightly in height and width again due to convolutional padding, but it now has more than twice as many feature layers! The combinations of low-level edges (lines and curves) now make more complex shapes (crosses and circles) that we can use to identify digits. Because this vocabulary of features is more complex, we need more layers to express them. Furthermore, we know that these new richer features are only the important features from the first convolutional layer because of the subsampling layer.
5) S4 (Subsampling 4) layer- This layer is 5 pixels high, 5 pixels wide, and 16 pixels deep. Same amount of features, but one quarter the size again. This is the last layer where we are maintaining a 2-dimensional view of the image. From here we take the 400 neurons (5 x 5 x 16) and turn them into a flat vector of 400 x 1.
6) C5 (Convolutional 5) layer- This layer is 120 pixels wide, and 1 pixel deep (it’s 2-dimensional, not 3-dimensional.) This layer is a combination of the features from the previous S4 layer. By dropping down from a 3-dimensional feature map to a 1-dimensional feature vector, we are indicating that we have all of the features extracted from the image that we need to decide on a concept. Now, we need to combine those features to figure out what the image is of.
7) F6 (Feature 6) layer- This layer is 60 pixels wide, and 1 pixel deep. Like before, it is a combination of features from the previous C5 layer. This is the final layer before we make a decision.
8) Output layer- This layer is 10 pixels wide, and 1 pixel deep. Why that size? Because we have ten possible labels (digits 0 through 9.) The output neuron that has the highest number from combinations of F6 features is the output of our network. This process is how the first image in this post is recognized as a 4.
Convolutional architectures, training practices, and layer types are often much more complex than this simple (yup) example and can take a large amount of data to train. Modern networks have hundreds of layers, and the inputs and outputs of each layer are often combinations of multiple previous layers. If you work with an AI vendor, like Clarifai, they’ll take care of the heavy lifting, design, and computation. Either way, CNNs are fascinating, intricate algorithms for AI, and hopefully, this blog post helps you get started on learning about this.






